
Board Layout:
It seems strange that the fan is actually larger than the hole in the top plate of the four part heatsink. The fan is a 50mm flat fins design, whilst the hole is strangely only 40mm across. The main portion of the heatsink is manufactured in copper and features a dual heat pipe design, running from directly above the core to the outer edges of the main portion of the heatsink. On the other hand, the outer shell that cools the BGA memory chips is cast in aluminium.

As we've noted, the heatsink gets hot, so it is doing a good job of removing heat from the GPU. However, as we've mentioned already, the fan is a little intermittent and can be rather noisy when you are least expecting it to be so.


The die is manufactured on TSMC's 90nm Low-k process technology, packing around 321 million transistors in to a 288mm² package. That is in comparison to the 301 million transistors packed in to NVIDIA's G70 GPU, which has a larger surface area of 334mm² - a direct consequence of manufactured on TSMC's larger 110nm process.
Architecture:
Since the launch of ATI's awesome Radeon 9700, we have not really seen much change in the core logic behind ATI's recent GPU's. However, with R520, they've made some telling changes in order to make positive steps in to the Shader Model 3.0 party. The whole architecture is focused around being as efficient as possible. That's not to say that NVIDIA's G70 is inefficient, its just that NVIDIA and ATI have adopted very different stances on how they perceive the perfect Shader Model 3.0 architecture - over time it will be up to the game developers to decide which of the two architectures is better than the other.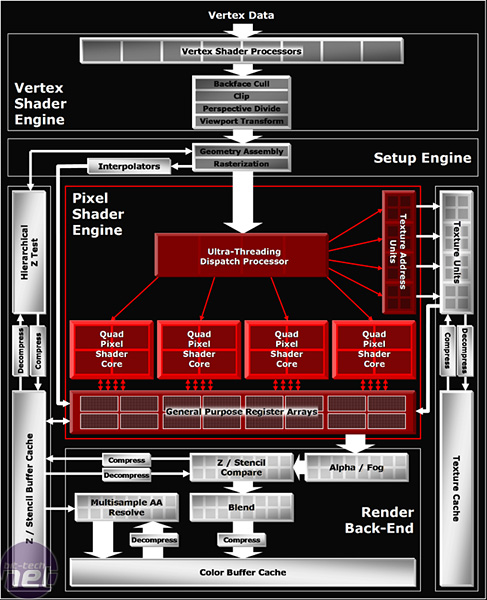
Full 128-bit precision... All of the time!
Until now, all of ATI's GPU's since Radeon 9700 have used FP24 in the pixel shader with no fall back for partial precision hints. The Radeon X1000 series is different. It utilises a full FP32 precision all of the time, meaning that partial precision hints in the game engine's code are simply ignored by ATI's new architecture in the same way that they were with all GPU's residing from R300. Essentially, this means that all shader instructions will be processed and completed using a full 128-bit floating point precision, through all of the Radeon X1000 series.This is slightly different from the way that NVIDIA go about things. Ever since the days of GeForce FX, NVIDIA adopted a partial precision method (FP16) in the pixel shader to improve performance. This meant that when full 128-bit floating point (FP32) precision wasn't required by the shader instruction, the architecture could fall back to a 64-bit floating point (FP16) precision, dependant on the game developer's use of partial precision hints in the game engine.
I guess the question you want to know the answer to is, 'Which method is better?' Well, ATI's method is fool proof and it doesn't matter what the game developer writes because it will always process the shader instructions with 128-bit floating point precision, but NVIDIA's hardware will make use of partial, 64-bit floating point, precision hints if the developer has chosen to use them. The problem with NVIDIA's method is that if the shader instructions that have been given a partial precision hint require more than 64-bit floating point precision, you will be greeted with artifacting problems due to a lack of precision. We've never seen this happen yet, but the fact that ATI don't use it at all means that they've got the speed to process all shader instructions with good performance at FP32.





MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.